








Updating and automating the covidpreprints.com website during the eLife Sprint 2020
13 October 2020
By Zhang-He Goh, Jonny Coates, Hugo Gruson
Cross-posted with rOpenSci
At the eLife Sprint in September 2020, we revamped the covidpreprints.com website, which aims at featuring landmark preprints on a timeline of the pandemic.
The birth of the project
The ongoing COVID-19 pandemic has led to about 35 million confirmed cases and over a million deaths worldwide. The looming spectre of a second wave of the pandemic has spurred around-the-clock research efforts to better understand the pathology and epidemiology of the virus, in the hope of new therapies and vaccines. And while novel scientific information about the pandemic was being shared at an unprecedented rate in the form of preprints1, it was becoming difficult to get an accurate, trustworthy record of this information.
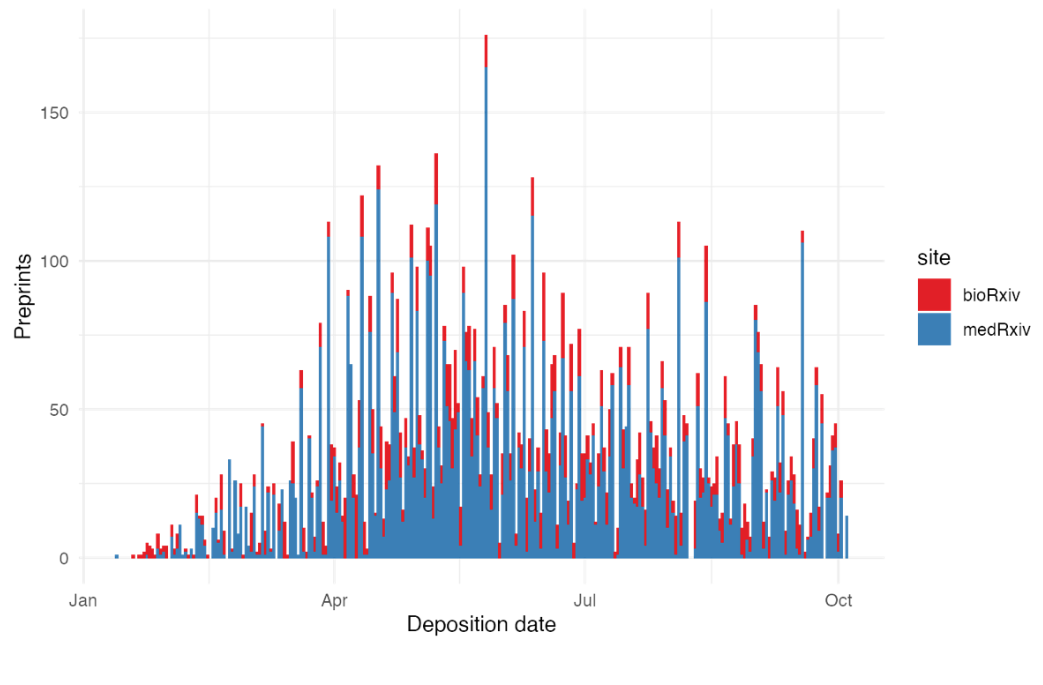
As a response to this explosive growth of COVID-related preprints, a small group of scientists from preLights published a list of important preprints, each accompanied by a short summary. The list quickly evolved into a full-fledged website: covidpreprints.com, with a timeline featuring landmark preprints side-by-side with key events in the pandemic.
But the team quickly faced a new problem: even the list of carefully selected preprints was becoming too long. This resulted in a cluttered interface that was difficult to navigate. Besides, the process to fetch the information related to each preprint (DOI, author names, link, etc.) was tedious and menial, which led to less frequent updates.
The makeover during eLife Sprint 2020
Fortunately, we identified a significant part of the process that could be automated by fetching information from the Europe PMC API. More precisely, this could be done directly in R with a single function call, thanks to rOpenSci’s europepmc2 package.
Here is a quick rundown of our update process:
- Get the list of preprint DOIs from a google sheet with the googlesheets43 package
- Fetch the preprint title, list of authors, link, and, if it has been reviewed and published, the journal name, using the europepmc package
- Get the altmetric score of each publication with the rAltmetric4 package, to provide readers with some information about the impact of each preprint, and the amount of discussion it sparked on social media.
(For further details of the code, check the post on rOpenSci)
The website is then automatically rebuilt and deployed each night with pkgdown5 and GitHub actions6. The use of pkgdown on GitHub pages greatly reduces the need for complex tools such as Shiny, and the necessity of a custom server. We believe this is an important step for the project’s long-term sustainability and to ease re-use of our code in other contexts.
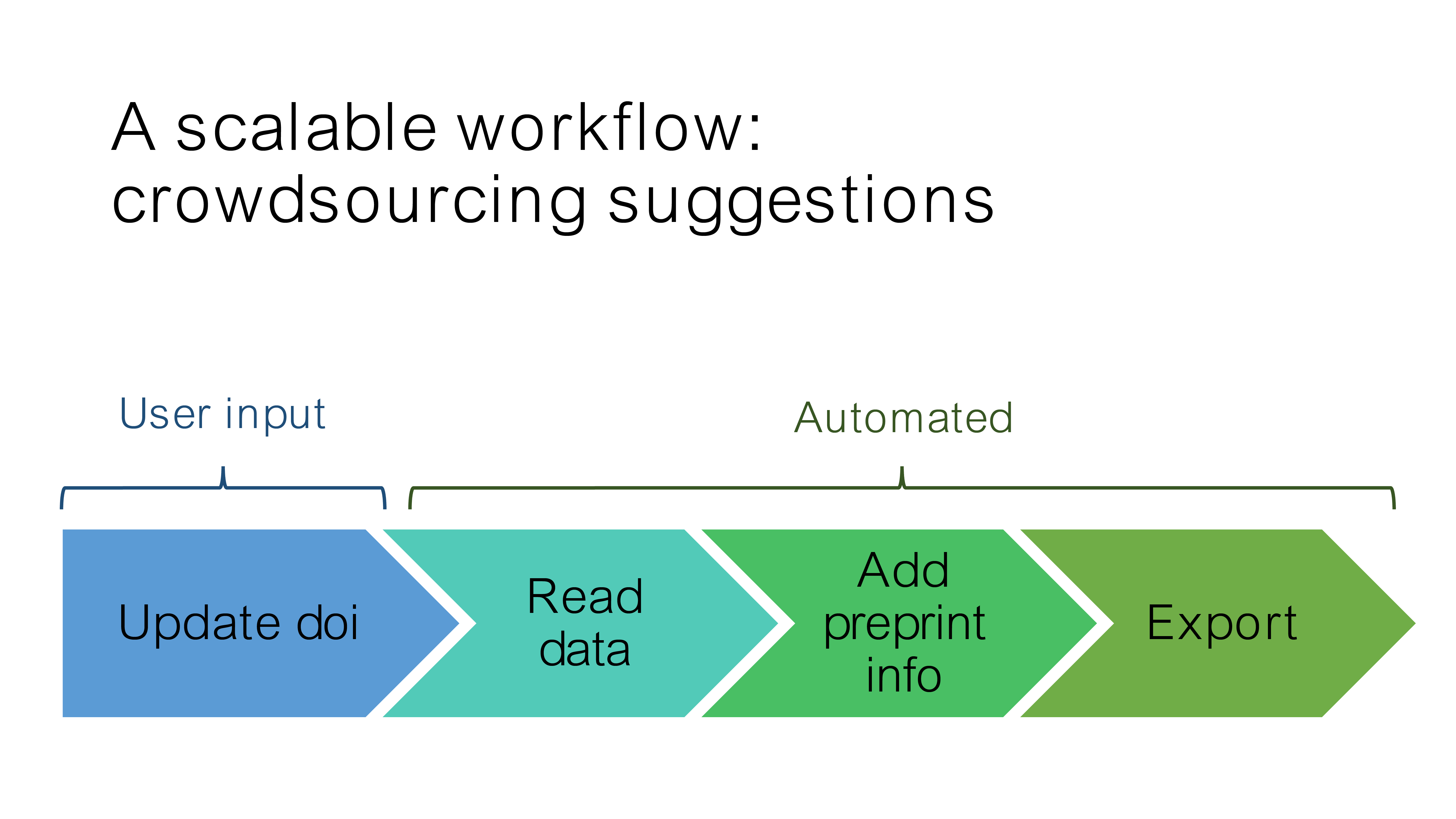
This scalable workflow allows us to focus on the scientific side of the process: select and highlight chosen preprints to track the progress of our knowledge on COVID-19. This also unlocks the ability to crowdsource reviews or suggestions for landmark preprints. Now, any netizen can nominate a preprint via this google form.
Alongside these under-the-hood changes, the project also went through a complete design makeover, because we believe it is important to make this information easy to read and understand for everybody. This work mainly resulted in a fresh design for the timeline and a new logo for the project.
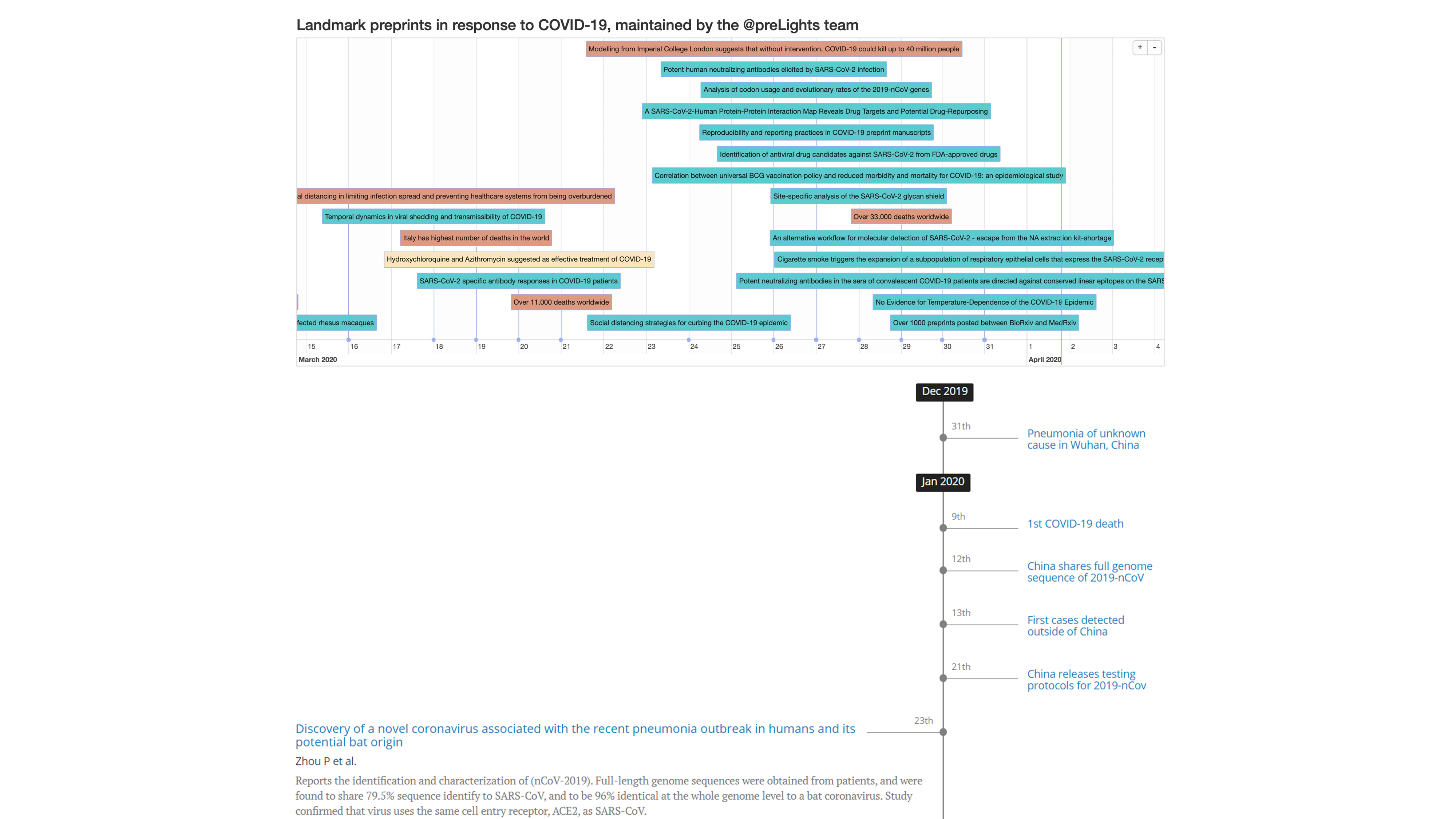
Future perspectives
Experts from all around the world are asking, “What have we learnt from this pandemic?” For now, we have some exciting new ideas moving forward with the project. In addition to expanding our sources by including more scientific communities and crowdsourced reviews from Outbreak Science PREreview on our website, we would also love to introduce preprint clustering, grouping preprints into themes that thread around them.
As advocates of preprints and open science, we are constantly mindful about how our project would remain relevant for years to come – in a future post-COVID-19. We hope that our website, with its new simplified workflow, will continue to serve as a set of tools that can be easily re-purposed to meet the next healthcare challenge and further combat misinformation: be it another infectious disease crisis or one that is caused by an endemic disease. To facilitate re-use of the project and improve long-term sustainability, we have drafted a maintenance document in the GitHub repository, which contains more technical information.
Conclusion
This project illustrates what can be achieved when different communities focused on various aspects of Open Science intersect: preLights came up with the original idea and maintains the website content, rOpenSci provided packages to perform otherwise difficult and menial tasks in just a couple of code lines, and finally eLife brought all these people together. We are truly amazed at how much was accomplished in a very short amount of time due to the great complementarity of skills of people from the different communities! Now, we hope to cordially invite every interested person to join us in our quest for promoting better information about health by either nominating preprints via the Google form or by contributing to the website code!
Acknowledgements
We’d like to thank both the original preLights team: Jonny Coates, Sejal Davla, Mariana De Niz, Gautam Dey, Zhang-He Goh, Debbie Ho, Kirsty Hooper, Lars Hubatsch, Sundar Naganathan, Máté Pálfy & Srivats Venkataramanan, as well as the eLife Sprint team:Hugo Gruson, Chris Huggins, Allan Ochola, Bruno Paranhos & Michael Parkin.
- Fraser, N., Brierley, L., Dey, G., Polka, J. K., Pálfy, M., Nanni, F., & Coates, J. A. (2020). Preprinting the COVID-19 pandemic. doi:10.1101/2020.05.22.111294
- Najko Jahn (2020). europepmc: R Interface to the Europe PubMed Central RESTful Web Service. R package version 0.4.
- Jenny Bryan (2020). googlesheets4: Access Google Sheets using the Sheets API V4. R package version 0.2.0.
- Karthik Ram (2017). rAltmetric: Retrieves Altmerics Data for Any Published Paper from ‘Altmetric.com’. R package version 0.7.0.
- Hadley Wickham, Jay Hesselberth (2020). pkgdown: Generate an attractive and useful website from a source package. R packager version 1.6.1.
- thanks to Maëlle Salmon & Steph Locke for the inspiration here with their workflow at https://lockedata.github.io/cransays/