








Nanopore-based genome assembly and the evolutionary genomics of basmati rice
Posted on: 19 September 2019
Preprint posted on 13 August 2019
What makes basmati rice differ from other varieties? How did they evolve? The sequencing of two high-quality basmati rice genomes provides clues to their evolutionary history.
Selected by Edi SudiantoCategories: evolutionary biology, genetics, genomics, plant biology
Background
Asian rice (Oryza sativa L.) is one of the most widely-consumed crops – feeding about half of the world’s population. Two subspecies of rice are formally recognized, short-grain subspecies japonica and long-grain subspecies indica (see review by [1]). There have contentious debates on how many domestication events shaped the current Asian rice varieties [2]. In addition to the two subspecies, other widely recognized varieties are aus and basmati (aromatic) rice. Basmati rice is unique as compared to other rice varieties as it is highly valued among the South Asian populations for its fragrant, long, and slender grains.
Here, the authors provide high-quality, chromosome-scale genome assemblies of two basmati rice landraces (Basmati 334 and Sufid) using long-read Nanopore sequencing platform. Unlike the more commonly used Illumina short-read sequences, Nanopore reads offer an opportunity to assemble a more contiguous genome. The two basmati rice genomes represent the untapped genetic information that was not readily available. With these genomes, the authors presented a comparative genomics study to disentangle the complex history of rice domestication and evolution.
Key findings
Expansion of copia-like retrotransposon in the basmati rice genomes
The two basmati rice genomes have had more repetitive DNA sequences than japonica rice. Among these repetitive DNA, retrotransposons constitute the highest proportion (~52%) in both genomes. In particular, the authors discovered that the two largest retrotransposon families, gypsy and copia, vary among four rice varieties (indica, japonica, aus, and basmati). Some retrotransposons are found to be specific to domesticated varieties, but could not be found in wild rice (single asterisk in Figure 1). In addition, several gypsy-like retrotransposons are specific to indica, aus, and basmati (double asterisk in Figure 1), while some copia-like repeats are only specific to basmati varieties (triple asterisk in Figure 1).
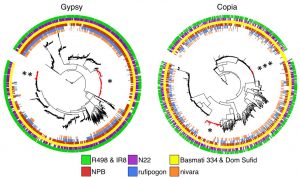
Figure 1. Phylogeny of two most abundant retrotransposon families, gypsy and copia, based on the rve gene among four rice cultivar types and two wild rice (Adapted from Figure 4C of the preprint).
Basmati rice has had extensive gene flow from aus rice
The origin of basmati rice variety has not yet been fully understood. Earlier studies have proposed that basmati rice is a hybrid between japonica and aus rice. In this preprint, the authors identified that the two basmati rice are closer to the japonica than indica or aus (Figure 2). However, further analyses also indicated that gene flows also play a role in shaping the evolution of rice varieties. Japonica rice variety is shown to have admixture events with O. rufipogon, while those of basmati-type rice has had gene exchanges with aus-type (Figure 2).
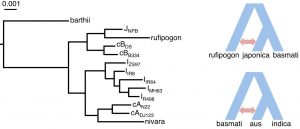
Figure 2. (Left) Maximum likelihood tree based on four-fold degenerate sites among the rice varieties. (Right) Model of gene flow events among domesticated Asian rice. cA, aus; cB, basmati; I, indica; J, japonica. (Adapted from Figure 5A and F of the preprint).
Population genomics point to three distinct genetic groups among basmati rice
With the availability of high-quality basmati rice genomes, the authors were able to perform population genomics study in this preprint to understand the diversity of this rice type. Basmati rice was shown to segregate into three distinct genetic groups based on their locality, including (1) Bhutan/Nepal, (2) India/Bangladesh/Myanmar, and (3) Iran/Pakistan groups (Figure 3). Group 2 (India/Bangladesh/Myanmar) is genetically more distinct than the other two groups, likely due to the continuous gene flows from aus varieties which are traditionally grown in these regions.
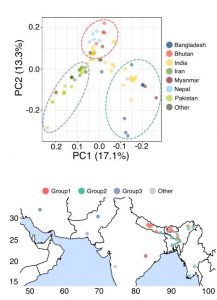
Figure 3. (Top) Principal component analysis (PCA) plot of the 78 basmati rice varieties based on the population genomic dataset. Dashed lines denote the genetic group segregation. (Bottom) The geographic locations of the basmati rice varieties. (Adapted from Figure 7A and C of the preprint).
Why I like this preprint
I chose this preprint as it provides a good example of Nanopore long-read application in generating the high-quality assembly of plant genomes. Plants are notorious for its complicated and repetitive-rich genomes. Long-read sequences, from either PacBio or Nanopore, have been anticipated to tackle these problems. In this preprint, the authors were able to reconstruct high-quality genome assemblies using Nanopore technology. These new genomes then can be used to address long-standing evolutionary questions, such as the origin and population genomics of basmati rice in this study.
Future directions and questions
- As mentioned in the conclusion, the two genomes provide additional genomic resources that can be used for further crop improvements. What kind of agronomic traits can we take from basmati rice?
- The two basmati rice genomes are highly syntenic to the Nipponbare genome, except for the pericentromeric region on chromosome 6. Are there any genes known to be located in this region? Does this inversion have any harmful effects on the basmati rice?
References
- Sweeney M and McCouch S. (2007). The complex history of the domesticated rice. Ann. Bot. 100: 951–957.
- Vaughan DA, Lu BR, Tomooka N. (2008). Was Asian rice (Oryza sativa) domesticated more than once? Rice 1: 16–24.
doi: https://doi.org/10.1242/prelights.13881
Read preprint (No Ratings Yet)
(No Ratings Yet)Sign up to customise the site to your preferences and to receive alerts
Register hereAlso in the evolutionary biology category:
Drift drives phenotypic evolution in a rapid island radiation
Zoha Sadaqat
Cell position is more important than cell shape or age for the acquisition of cell identity in the brown alga Ectocarpus
Urvashi Goswami
Inhibition of the gut ceramidase Asah2 decelerates the vertebrate ageing rate
Jeny Jose
Also in the genetics category:
Comprehensive Lineage Tracing Maps the Landscape of Cell Fate Decisions in Mouse Embryogenesis
Béryl Laplace-Builhé, Lucie Hermet
Combinatorial and Inducible CRISPRa/i Enables Canalized hiPSC Forward Programming and Iterative Refinement via Single-Cell Genomics
Cell-ID
Site-Specific Inhibition of Translation Initiation via 2’-O-methylation
Leonie Brüne
Also in the genomics category:
Comprehensive Lineage Tracing Maps the Landscape of Cell Fate Decisions in Mouse Embryogenesis
Béryl Laplace-Builhé, Lucie Hermet
Combinatorial and Inducible CRISPRa/i Enables Canalized hiPSC Forward Programming and Iterative Refinement via Single-Cell Genomics
Cell-ID
Inhibition of the gut ceramidase Asah2 decelerates the vertebrate ageing rate
Jeny Jose
Also in the plant biology category:
A drought stress-induced MYB transcription factor regulates pavement cell shape in leaves of European aspen (Populus tremula)
Jeny Jose
Actin Counters Geometry to Guide Plant Cell Division
Jeny Jose
The nucleus follows an internal cellular scale during polarized root hair cell development
Jeny Jose
preLists in the evolutionary biology category:
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
November in preprints – DevBio & Stem cell biology
preLighters with expertise across developmental and stem cell biology have nominated a few developmental and stem cell biology (and related) preprints posted in November they’re excited about and explain in a single paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Aline Grata et al. |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
preLights peer support – preprints of interest
This is a preprint repository to organise the preprints and preLights covered through the 'preLights peer support' initiative.
| List by | preLights peer support |
EMBO | EMBL Symposium: The organism and its environment
This preList contains preprints discussed during the 'EMBO | EMBL Symposium: The organism and its environment', organised at EMBL Heidelberg, Germany (May 2023).
| List by | Girish Kale |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
EMBL Synthetic Morphogenesis: From Gene Circuits to Tissue Architecture (2021)
A list of preprints mentioned at the #EESmorphoG virtual meeting in 2021.
| List by | Alex Eve |
Planar Cell Polarity – PCP
This preList contains preprints about the latest findings on Planar Cell Polarity (PCP) in various model organisms at the molecular, cellular and tissue levels.
| List by | Ana Dorrego-Rivas |
TAGC 2020
Preprints recently presented at the virtual Allied Genetics Conference, April 22-26, 2020. #TAGC20
| List by | Maiko Kitaoka et al. |
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
COVID-19 / SARS-CoV-2 preprints
List of important preprints dealing with the ongoing coronavirus outbreak. See http://covidpreprints.com for additional resources and timeline, and https://connect.biorxiv.org/relate/content/181 for full list of bioRxiv and medRxiv preprints on this topic
| List by | Dey Lab, Zhang-He Goh |
1
SDB 78th Annual Meeting 2019
A curation of the preprints presented at the SDB meeting in Boston, July 26-30 2019. The preList will be updated throughout the duration of the meeting.
| List by | Alex Eve |
Pattern formation during development
The aim of this preList is to integrate results about the mechanisms that govern patterning during development, from genes implicated in the processes to theoritical models of pattern formation in nature.
| List by | Alexa Sadier |
Also in the genetics category:
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
September in preprints – Cell biology edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading list. This month, categories include: (1) Cell organelles and organisation, (2) Cell signalling and mechanosensing, (3) Cell metabolism, (4) Cell cycle and division, (5) Cell migration
| List by | Sristilekha Nath et al. |
July in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell Signalling and Mechanosensing (2) Cell Cycle and Division (3) Cell Migration and Cytoskeleton (4) Cancer Biology (5) Cell Organelles and Organisation
| List by | Girish Kale et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
March in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) cancer biology 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics and genomics 6) other
| List by | Girish Kale et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
Early 2025 preprints – the genetics & genomics edition
In this community-driven preList, a group of preLighters, with expertise in different areas of genetics and genomics have worked together to create this preprint reading list. Categories include: 1) bioinformatics 2) epigenetics 3) gene regulation 4) genomics 5) transcriptomics
| List by | Chee Kiang Ewe et al. |
January in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Barbora Knotkova et al. |
End-of-year preprints – the genetics & genomics edition
In this community-driven preList, a group of preLighters, with expertise in different areas of genetics and genomics have worked together to create this preprint reading list. Categories include: 1) genomics 2) bioinformatics 3) gene regulation 4) epigenetics
| List by | Chee Kiang Ewe et al. |
BSDB/GenSoc Spring Meeting 2024
A list of preprints highlighted at the British Society for Developmental Biology and Genetics Society joint Spring meeting 2024 at Warwick, UK.
| List by | Joyce Yu, Katherine Brown |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Alumni picks – preLights 5th Birthday
This preList contains preprints that were picked and highlighted by preLights Alumni - an initiative that was set up to mark preLights 5th birthday. More entries will follow throughout February and March 2023.
| List by | Sergio Menchero et al. |
Semmelweis Symposium 2022: 40th anniversary of international medical education at Semmelweis University
This preList contains preprints discussed during the 'Semmelweis Symposium 2022' (7-9 November), organised around the 40th anniversary of international medical education at Semmelweis University covering a wide range of topics.
| List by | Nándor Lipták |
20th “Genetics Workshops in Hungary”, Szeged (25th, September)
In this annual conference, Hungarian geneticists, biochemists and biotechnologists presented their works. Link: http://group.szbk.u-szeged.hu/minikonf/archive/prg2021.pdf
| List by | Nándor Lipták |
2nd Conference of the Visegrád Group Society for Developmental Biology
Preprints from the 2nd Conference of the Visegrád Group Society for Developmental Biology (2-5 September, 2021, Szeged, Hungary)
| List by | Nándor Lipták |
EMBL Conference: From functional genomics to systems biology
Preprints presented at the virtual EMBL conference "from functional genomics and systems biology", 16-19 November 2020
| List by | Jesus Victorino |
TAGC 2020
Preprints recently presented at the virtual Allied Genetics Conference, April 22-26, 2020. #TAGC20
| List by | Maiko Kitaoka et al. |
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
Autophagy
Preprints on autophagy and lysosomal degradation and its role in neurodegeneration and disease. Includes molecular mechanisms, upstream signalling and regulation as well as studies on pharmaceutical interventions to upregulate the process.
| List by | Sandra Malmgren Hill |
Zebrafish immunology
A compilation of cutting-edge research that uses the zebrafish as a model system to elucidate novel immunological mechanisms in health and disease.
| List by | Shikha Nayar |
Also in the genomics category:
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
November in preprints – DevBio & Stem cell biology
preLighters with expertise across developmental and stem cell biology have nominated a few developmental and stem cell biology (and related) preprints posted in November they’re excited about and explain in a single paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Aline Grata et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
March in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) cancer biology 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics and genomics 6) other
| List by | Girish Kale et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
Early 2025 preprints – the genetics & genomics edition
In this community-driven preList, a group of preLighters, with expertise in different areas of genetics and genomics have worked together to create this preprint reading list. Categories include: 1) bioinformatics 2) epigenetics 3) gene regulation 4) genomics 5) transcriptomics
| List by | Chee Kiang Ewe et al. |
End-of-year preprints – the genetics & genomics edition
In this community-driven preList, a group of preLighters, with expertise in different areas of genetics and genomics have worked together to create this preprint reading list. Categories include: 1) genomics 2) bioinformatics 3) gene regulation 4) epigenetics
| List by | Chee Kiang Ewe et al. |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Semmelweis Symposium 2022: 40th anniversary of international medical education at Semmelweis University
This preList contains preprints discussed during the 'Semmelweis Symposium 2022' (7-9 November), organised around the 40th anniversary of international medical education at Semmelweis University covering a wide range of topics.
| List by | Nándor Lipták |
20th “Genetics Workshops in Hungary”, Szeged (25th, September)
In this annual conference, Hungarian geneticists, biochemists and biotechnologists presented their works. Link: http://group.szbk.u-szeged.hu/minikonf/archive/prg2021.pdf
| List by | Nándor Lipták |
EMBL Conference: From functional genomics to systems biology
Preprints presented at the virtual EMBL conference "from functional genomics and systems biology", 16-19 November 2020
| List by | Jesus Victorino |
TAGC 2020
Preprints recently presented at the virtual Allied Genetics Conference, April 22-26, 2020. #TAGC20
| List by | Maiko Kitaoka et al. |
Also in the plant biology category:
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
The Society for Developmental Biology 82nd Annual Meeting
This preList is made up of the preprints discussed during the Society for Developmental Biology 82nd Annual Meeting that took place in Chicago in July 2023.
| List by | Joyce Yu, Katherine Brown |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
SDB 78th Annual Meeting 2019
A curation of the preprints presented at the SDB meeting in Boston, July 26-30 2019. The preList will be updated throughout the duration of the meeting.
| List by | Alex Eve |