








MINERVA: A facile strategy for SARS-CoV-2 whole genome deep sequencing of clinical samples
Posted on: 28 April 2020 , updated on: 22 November 2021
Preprint posted on 25 April 2020
Article now published in Molecular Cell at http://dx.doi.org/10.1016/j.molcel.2020.11.030
Learning from the past and preparing for the future: Development of a swift and easy RNA sequencing technique on rapidly evolving viral strains
Selected by Yasmin LauCategories: biochemistry, molecular biology
Background
In a matter of months, the cases of SARS-CoV-2 have transformed from an outbreak within a small community in Wuhan into a global pandemic, causing over 200,000 deaths worldwide as of today. Undoubtedly, SARS-CoV-2 has spread on an exponential scale, which has drastically increased the demand for medical resources, clinical testing and research.
Previously, conventional next-generation sequencing has been implemented on building viral whole genome libraries. This method utilizes double-strand DNA ligation (dsDL) steps based on the viral RNA (1) and ultimately extracts the meta transcriptome of one virus species from a patient sample. While this conventional workflow is effective in capturing the viral meta transcriptome, it is often costly and time consuming as it requires lengthy hands-on protocols. Due to the low abundance of the virus in patient samples (2), it is not uncommon that additional steps are required for target enrichment to achieve higher coverage of the genome. Given that coronaviruses like SARS-CoV-2 are rapidly evolving, these time-consuming and laborious protocols pose limitations for routine and large-volume use.
In this preprint, the authors describe an optimized viral RNA sequencing technique MINERVA (Metagenomic RNA enrichment viral sequencing). This technique couples a previously reported methodology SHERRY (Sequencing Hetero RNA-DNA hybrid) with a fast sequence enrichment protocol.
Key Findings
MINERVA is a two-stage strategy involving SHERRY, then target enrichment
The first stage that already reduces timely hands-on steps compared to conventional RNA-seq methods is the SHERRY protocol. Instead of standard ligation of dsDNA fragments which requires several purification steps, SHERRY introduces the transposase Tn5 from bacteria which tags RNA/DNA fragments, cut dsDNA and ligate these fragments to adaptors (1). Subsequently, this creates a library of RNA/DNA hybrids which are then amplified with PCR (1).
The second stage is target enrichment. This involves quantification of SARS-CoV-2 in the sequencing library with qPCR, pooling, and then hybridization of RNA probes as bait with the amplified to target the post-RT-PCR dsDNA, thus enriching the sequences of interest (Fig. 1).
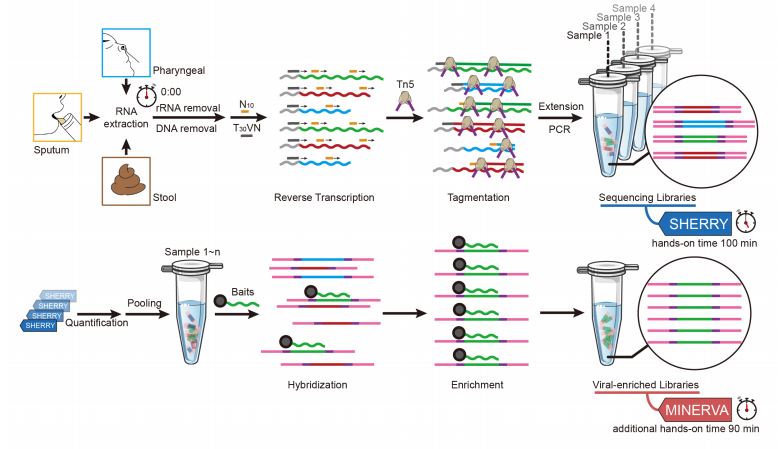
Figure 1: The MINERVA workflow including SHERRY and subsequent target enrichment
Use of MINERVA resulted in higher SARS-CoV-2 genome coverage than in conventional sequencing techniques involving dsDL
Following sequencing using both MINERVA and dsDL, both libraries contained low but detectable levels of SARS-CoV-2 sequences. However, it was found that the viral sequence ratio in MINERVA libraries was higher than that of dsDL. Moreover, while only performing SHERRY yielded a relatively low viral ratio and depth (number of reads per sample), performing MINERVA afterwards augmented the sequence ratio by 10,000-fold. When including RT-qPCR data, there were higher coverage and depth from MINERVA than dsDL taken from pharyngeal, sputum and stool samples based on Ct values.
MINERVA can be used to detect SARS-CoV-2 genetic variants
Previous studies have shown that different genetic variants of coronaviruses can exist within the same host. The authors therefore sought to investigate the performance of MINERVA in detecting these in 85 samples from COVID19 patients. Several mutations were identified within the viral sequence, in which C241T, C3037T, C11408T and A23403G were present in the most samples out of the 85. Variant allele frequencies were also plotted for each sample. Some samples were found to only have one mutation of two high-linked positions; for example, 13 were found to have T28144C, but only 7 of these also had C8782T. Considering this data, it was concluded that MINERVA can indeed detect genetic variants of SARS-CoV-2 within the same sample.
Why I like this preprint
I first heard about SARS-CoV-2 in December 2019 from a family member in Hong Kong. Initially, this topic was considered and discussed mostly in a light-hearted manner by many people around me in the UK, myself included. Little did we know that this virus would spread so rapidly and exponentially. At this moment in time, it is essential to utilise all we can to advance the research on understanding the viral genome and identify possible routes of vaccine development.
This preprint introduces an optimised strategy for RNA sequencing which is built upon previous techniques. It utilises the high throughput aspects of classical RNA-seq protocols, while expediting the process with SHERRY without compromising meta-transcriptomic information. Not only does it provide a more practical approach in routine sequencing for the current pandemic, it also brings us one step closer to prepare for future potential pandemics.
Questions for authors
1. Considering the data from genetic variants sequenced with MINERVA in SARS-CoV-2, as well as previous beta coronaviruses like SARS-CoV and MERS, is there a way to predict the likelihood of specific mutations for any future corona viruses?
2. It was mentioned that meta-transcriptomic information is lost during the initial steps of RT-PCR in conventional dsDL. Given that MINERVA also requires RT-PCR, are there any differences in the SHERRY RT-PCR compared to dsDL that overcomes this problem?
References
- Di, L.; Sun, Y.; Liu, L. et al. RNA sequencing by direct tagmentation of RNA/DNA hybrids. Natl. Acad. Sci. USA 2020, 117(6), 2886-2893.
- Wolfel, R.; Corman, V.M.; Guggemos, W. et al. Virological assessment of hospitalized patients with COVID-2019. Nature 2020.
doi: https://doi.org/10.1242/prelights.19673
Read preprint (No Ratings Yet)
(No Ratings Yet)Sign up to customise the site to your preferences and to receive alerts
Register hereAlso in the biochemistry category:
Site-Specific Inhibition of Translation Initiation via 2’-O-methylation
Leonie Brüne
Inhibition of VP2-mediated entry: a potential antiviral strategy to treat or prevent calicivirus disease
Orestis Savva
Inhibition of the gut ceramidase Asah2 decelerates the vertebrate ageing rate
Jeny Jose
Also in the molecular biology category:
Disordered protein COSA-2 maintains crossover-specific repair compartments to ensure meiotic crossover maturation
Chee Kiang Ewe
Combinatorial and Inducible CRISPRa/i Enables Canalized hiPSC Forward Programming and Iterative Refinement via Single-Cell Genomics
Cell-ID
Defective BRCA1-mediated DNA end resection drives tandem duplication formation and FANCM synthetic lethality
Marta San Martin
preLists in the biochemistry category:
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
September in preprints – Cell biology edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading list. This month, categories include: (1) Cell organelles and organisation, (2) Cell signalling and mechanosensing, (3) Cell metabolism, (4) Cell cycle and division, (5) Cell migration
| List by | Sristilekha Nath et al. |
July in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell Signalling and Mechanosensing (2) Cell Cycle and Division (3) Cell Migration and Cytoskeleton (4) Cancer Biology (5) Cell Organelles and Organisation
| List by | Girish Kale et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
February in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry and cell metabolism 2) cell organelles and organisation 3) cell signalling, migration and mechanosensing
| List by | Barbora Knotkova et al. |
Community-driven preList – Immunology
In this community-driven preList, a group of preLighters, with expertise in different areas of immunology have worked together to create this preprint reading list.
| List by | Felipe Del Valle Batalla et al. |
January in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Barbora Knotkova et al. |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
Peer Review in Biomedical Sciences
Communication of scientific knowledge has changed dramatically in recent decades and the public perception of scientific discoveries depends on the peer review process of articles published in scientific journals. Preprints are key vehicles for the dissemination of scientific discoveries, but they are still not properly recognized by the scientific community since peer review is very limited. On the other hand, peer review is very heterogeneous and a fundamental aspect to improve it is to train young scientists on how to think critically and how to evaluate scientific knowledge in a professional way. Thus, this course aims to: i) train students on how to perform peer review of scientific manuscripts in a professional manner; ii) develop students' critical thinking; iii) contribute to the appreciation of preprints as important vehicles for the dissemination of scientific knowledge without restrictions; iv) contribute to the development of students' curricula, as their opinions will be published and indexed on the preLights platform. The evaluations will be based on qualitative analyses of the oral presentations of preprints in the field of biomedical sciences deposited in the bioRxiv server, of the critical reports written by the students, as well as of the participation of the students during the preprints discussions.
| List by | Marcus Oliveira et al. |
CellBio 2022 – An ASCB/EMBO Meeting
This preLists features preprints that were discussed and presented during the CellBio 2022 meeting in Washington, DC in December 2022.
| List by | Nadja Hümpfer et al. |
20th “Genetics Workshops in Hungary”, Szeged (25th, September)
In this annual conference, Hungarian geneticists, biochemists and biotechnologists presented their works. Link: http://group.szbk.u-szeged.hu/minikonf/archive/prg2021.pdf
| List by | Nándor Lipták |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
EMBL Seeing is Believing – Imaging the Molecular Processes of Life
Preprints discussed at the 2019 edition of Seeing is Believing, at EMBL Heidelberg from the 9th-12th October 2019
| List by | Dey Lab |
Cellular metabolism
A curated list of preprints related to cellular metabolism at Biorxiv by Pablo Ranea Robles from the Prelights community. Special interest on lipid metabolism, peroxisomes and mitochondria.
| List by | Pablo Ranea Robles |
MitoList
This list of preprints is focused on work expanding our knowledge on mitochondria in any organism, tissue or cell type, from the normal biology to the pathology.
| List by | Sandra Franco Iborra |
Also in the molecular biology category:
Developmental regulation: molecular and ecological niches
This conference was held at the Station Biologique de Roscoff (France) and brought together researchers exploring how diverse niche environments shape developmental processes across scales. Spanning topics from ecological and metabolic influences to signalling networks, mechanics and gene regulation, the meeting highlighted the interplay between intrinsic and extrinsic factors in controlling cell fate and tissue organisation. This preList gathers preprints discussed by speakers and poster presenters during the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
September in preprints – Cell biology edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading list. This month, categories include: (1) Cell organelles and organisation, (2) Cell signalling and mechanosensing, (3) Cell metabolism, (4) Cell cycle and division, (5) Cell migration
| List by | Sristilekha Nath et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
February in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry and cell metabolism 2) cell organelles and organisation 3) cell signalling, migration and mechanosensing
| List by | Barbora Knotkova et al. |
Community-driven preList – Immunology
In this community-driven preList, a group of preLighters, with expertise in different areas of immunology have worked together to create this preprint reading list.
| List by | Felipe Del Valle Batalla et al. |
January in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Barbora Knotkova et al. |
2024 Hypothalamus GRC
This 2024 Hypothalamus GRC (Gordon Research Conference) preList offers an overview of cutting-edge research focused on the hypothalamus, a critical brain region involved in regulating homeostasis, behavior, and neuroendocrine functions. The studies included cover a range of topics, including neural circuits, molecular mechanisms, and the role of the hypothalamus in health and disease. This collection highlights some of the latest advances in understanding hypothalamic function, with potential implications for treating disorders such as obesity, stress, and metabolic diseases.
| List by | Nathalie Krauth |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Alumni picks – preLights 5th Birthday
This preList contains preprints that were picked and highlighted by preLights Alumni - an initiative that was set up to mark preLights 5th birthday. More entries will follow throughout February and March 2023.
| List by | Sergio Menchero et al. |
CellBio 2022 – An ASCB/EMBO Meeting
This preLists features preprints that were discussed and presented during the CellBio 2022 meeting in Washington, DC in December 2022.
| List by | Nadja Hümpfer et al. |
EMBL Synthetic Morphogenesis: From Gene Circuits to Tissue Architecture (2021)
A list of preprints mentioned at the #EESmorphoG virtual meeting in 2021.
| List by | Alex Eve |
FENS 2020
A collection of preprints presented during the virtual meeting of the Federation of European Neuroscience Societies (FENS) in 2020
| List by | Ana Dorrego-Rivas |
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
Lung Disease and Regeneration
This preprint list compiles highlights from the field of lung biology.
| List by | Rob Hynds |