








Deep Learning-Based Point-Scanning Super-Resolution Imaging
Posted on: 30 September 2019
Preprint posted on 7 September 2019
Article now published in Nature Methods at http://dx.doi.org/10.1038/s41592-021-01080-z
PSSR: A smart alternative to overcome the eternal triangle of compromise of point scanning imaging systems.
Selected by Mariana De NizCategories: bioinformatics, cell biology, microbiology, pathology, physiology
Background
In microscopy, the ‘eternal triangle of compromise’ states that for a given signal-to-noise ratio (the ratio between the amount of signal (photons) and the amount of noise in an image), improving any corner of the triangle, i.e. resolution, system sensitivity, or imaging speed, will come at the cost of the other corners for a given photon budget (Figure 1). Improvement in all corners can only be achieved when either the photon number or the SNR can be increased. However, an increase in detected photons, is achieved by either increasing the laser power, or improving the detector’s collection efficiency. But increasing the laser power may come at the cost of sample integrity, and improving collection efficiency comes at the cost of acquisition speed. Altogether, within a point-scanning system, it is impossible to optimize one parameter without compromising at least one of the others.
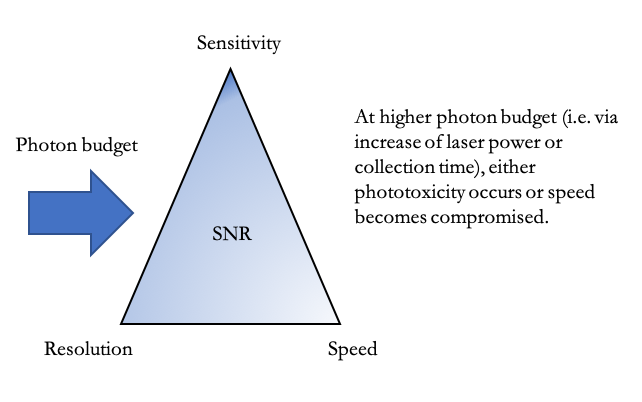
Despite these limitations, point scanning imaging systems are widely used tools for high resolution imaging. These include scanning electron microscopes and laser scanning confocal microscopes (LSM). Moreover, deep learning is an established method for image analysis and segmentation, and more recently, for restoration of microscopy images from noisy or low-resolution acquisitions to high resolution outputs (1-11). While current acquisition methods of point-scanning systems allow for useful analyses, a method that allows obtaining higher resolution ultrastructural information without the limitations of the ‘eternal triangle of compromise’ would be of great use.
Key findings and developments
General findings and developments
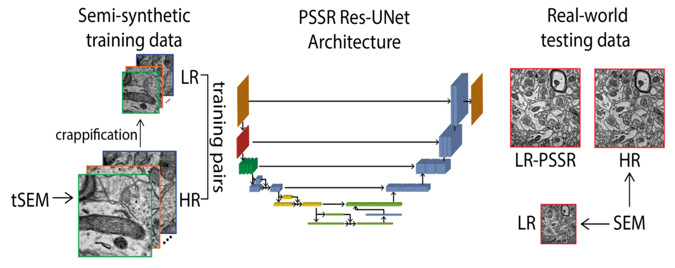
- To overcome the limitations of the ‘eternal triangle of compromise’, Fang et al introduce a deep learning-based super-sampling method for under-sampled images, which they term Point-Scanning Super-Resolution (PSSR) imaging (12) (Figure 2).
- They show that deep learning-based restoration of under-sampled images facilitates faster, lower dose imaging on both SEM and scanning confocal microscopes, which allows for smaller number of pixels acquired.
- The PSSR approach enables increasing the spatiotemporal resolution of point scanning imaging systems to previously unattainable levels, and overcomes limitations imposed by sample damage or imaging speed when imaging at full pixel resolution.
Specific developments
Model generation
- To train the model, many perfectly aligned high- and low- resolution image pairs are needed.
- Instead of manually acquiring high- and low-resolution image pairs, oversampled images acquired in SEM or LSM Airyscan microscopes were ‘crappified’ and then used to train the model for restoring under-sampled images.
- For ‘crappification’, the high-resolution images underwent Gaussian blurring, random pixel shifts, random salt-and-pepper noise addition, and 16x down-sampling of the pixel resolution.
Electron Microscopy
- The EM PSSR–based restoration of under-sampled images was reproducible using various microscopes and preparation methods even though it was only trained on data collected from one type of EM modality – transmission mode SEM. For this study, ultrathin sections from the hippocampus of a Long Evans male rat were used.
- Usually deep learning-based image restoration models are extremely sensitive to variations, including the model and training images, sample preparation, or the equipment used for image acquisition. The authors tested various microscopes, samples, and metrics (including PSNR, SSIM, FRC, NanoJ-SQUIRREL error mapping analysis and visual inspection) and found that PSSR was effective for restoring low resolution images.
- One major concern with deep learning-based image processing is accuracy, and in particular, the possibility of false positives (‘hallucinations’). The authors measured the PSNR and SSIM of low- and high-resolution images, and then super-sampled the low-resolution images by bilinear interpolation (LR-Bilinear) and PSSR model (LR-PSSR), and found that LR-PSSR significantly outperforms LR-Bilinear, and yields more accurate segmentation.
- Altogether, the ability to reliably 16x super-sample lower resolution datasets presents an opportunity to increase the throughput of SEM imaging by at least one order of magnitude.
Laser scanning confocal microscopy and live imaging
- For fluorescence, a LSM880 Airyscan microscope was used. Using the PSSR, 100x lower laser dose and 16x higher frame rates than those corresponding high-resolution acquisitions.
- In addition to fixed sample imaging, the authors sought to determine whether PSSR might provide a viable strategy for increasing the speed and lower the photon dose for live scanning confocal microscopy. As proof of concept, they trained the model on live cell timelapses of mitochondria in U2OS cells. While LR acquisitions were noisy and pixelated due to undersampling, they also showed less photobleaching. PSSR processing reduced the noise and increased the resolution of the LR acquisitions.
- To improve the performance of PSSR for timelapse data, the authors modified the design of the PSSR ResU-Net architecture, and trained the models on 5 timepoints at a time (MultiFrame-PSSR, or PSSR-MF). The improved speed, resolution, and SNR using PSSR-MF enabled detection of mitochondrial fission events that were not detectable in the LR or LR-Bilinear images.
- In conclusion, PSSR facilitates point scanning image acquisition with otherwise unattainable resolution, speed and sensitivity.
What I like about this paper
As previous work by the Manor lab, I like a lot the idea of open science, and the openness with which his lab communicates the work performed. I also like that this work addresses a limitation that many labs using microscopy across the world face. As a scientist I give great value to method development, and to the open dissemination of such methods. This helps advance science, and puts the necessary tools in the hands of as many scientists as possible. I found PSSR to be ingenious and extremely useful.
Open questions
*Note: all author answers are in section below.
- You mention in your discussion that although for various types of structures you analysed (e.g. mitochondria), you do not rule out the possibility that other structures may not be restored by your model with sufficient accuracy. Could you discuss a bit further which are the structures you think could be more challenging for your model, and why this might be the case?
- You discuss also that fluorescence data has the potential to be much more variable than EM data, and the relevance of this for training the model for a specific sample type. Equally, you discuss elsewhere in your manuscript the importance of the system and sample preparation for the model. For some time I have been aware of ideas by different people, to create open access repositories for microscopy-derived data, to which the scientific community of all fields of research can contribute. Do you think the direction you and other labs are exploring on deep learning for image analysis, would make such repository an even more appealing, and eventually even necessary prospect?
- In terms of sample preparation, was there anything specific you faced, which makes it easier (or more challenging) to train the model?
- What are the main limitations of the model when applied to live microscopy?
- Could you explain a bit further, why you used the progressive resizing and the discriminative learning rates only for EM, while you used only the best model preservation only for fluorescence?
- You mention in your discussion that in the near future it might be possible to generate generalized models for specific imaging systems, rather than sample types. Could you discuss further your thoughts on this aspect?
References
- Wang, Z., Chen, J. & Hoi, S. C. H. Deep Learning for Image Super-resolution: A Survey. eprint arXiv:1902.06068, arXiv:1902.06068 (2019).
- Jain, V. et al. Supervised Learning of Image Restoration with Convolutional Networks. (2007).
- Moen, E. et al. Deep learning for cellular image analysis. Nat Methods, doi:10.1038/s41592-019-0403-1 (2019).
- Weigert, M. et al. Content-aware image restoration: pushing the limits of fluorescence microscopy. Nat Methods 15, 1090-1097, doi:10.1038/s41592-018-0216-7 (2018).
- Wang, H. et al. Deep learning enables cross-modality super-resolution in fluorescence microscopy. Nat Methods 16, 103-110, doi:10.1038/s41592-018-0239-0 (2019).
- Ouyang, W., Aristov, A., Lelek, M., Hao, X. & Zimmer, C. Deep learning massively accelerates super- resolution localization microscopy. Nat Biotechnol 36, 460-468, doi:10.1038/nbt.4106 (2018).
- Nelson, A. J. & Hess, S. T. Molecular imaging with neural training of identification algorithm (neural network localization identification). Microsc Res Tech 81, 966-972, doi:10.1002/jemt.23059 (2018).
- Li, Y. et al. DLBI: deep learning guided Bayesian inference for structure reconstruction of super- resolution fluorescence microscopy. Bioinformatics 34, i284-i294, doi:10.1093/bioinformatics/bty241 (2018).
- Buchholz, T. O. et al. Content-aware image restoration for electron microscopy. Methods Cell Biol 152, 277-289, doi:10.1016/bs.mcb.2019.05.001 (2019).
- Guo, M. et al. Accelerating iterative deconvolution and multiview fusion by orders of magnitude. bioRxiv, 647370, doi:10.1101/647370 (2019).
- Batson, J. & Royer, L. Noise2self: Blind denoising by self-supervision. arXiv preprint arXiv:1901.11365 (2019).
- Fang L., et al. Deep Learning-Based Point-Scanning Super-Resolution imaging, bioRxiv, doi:10.1101/740548 (2019).
doi: https://doi.org/10.1242/prelights.14130
Read preprint (No Ratings Yet)
(No Ratings Yet)Sign up to customise the site to your preferences and to receive alerts
Register hereAlso in the bioinformatics category:
Temporal degradation of PRC2 uncovers specific developmental dependencies
María Mariner-Faulí
Science should be machine-readable
Theodora Stougiannou
Remote homology and functional genetics unmask deeply preserved Scm3/HJURP orthologs in metazoans
Reinier Prosee
Also in the cell biology category:
Combinatorial and Inducible CRISPRa/i Enables Canalized hiPSC Forward Programming and Iterative Refinement via Single-Cell Genomics
Cell-ID
Developmental conversion of the nucleolus into an RNA Polymerase II transcriptional platform in Drosophila spermatocytes
Panagiotis Giannios
Cell position is more important than cell shape or age for the acquisition of cell identity in the brown alga Ectocarpus
Urvashi Goswami
Also in the microbiology category:
Circadian Clock Programming of Anticipatory Antiviral Immunity Gates Enteric Virus Infection Susceptibility
Owen Ang
Inhibition of VP2-mediated entry: a potential antiviral strategy to treat or prevent calicivirus disease
Orestis Savva
Gut microbiome changes over the course of multiple sclerosis differentially influence autoimmune neuroinflammation
Carole Djagang et al.
Also in the pathology category:
Behavioral characteristics of an extremely old rhesus macaque in a zoo: Dementia-like symptoms and implications for quality of life of geriatric animals
Stefan Friedrich Wirth
EBV reprograms autoreactive anti-CNS B cells as antigen presenting cells in multiple sclerosis
Léa Bastien et al.
Clinically reported covert cerebrovascular disease and risk of neurological disease: a whole-population cohort of 367,988 people using natural language processing
Rafidah Mumtahinah Chowdhury et al.
Also in the physiology category:
Inhibition of the gut ceramidase Asah2 decelerates the vertebrate ageing rate
Jeny Jose
Feeding and reproduction of a tropical coastal copepod across warming and copper gradients
Tina Nguyen
Resilience to cardiac aging in Greenland shark Somniosus microcephalus
Theodora Stougiannou
preLists in the bioinformatics category:
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Alumni picks – preLights 5th Birthday
This preList contains preprints that were picked and highlighted by preLights Alumni - an initiative that was set up to mark preLights 5th birthday. More entries will follow throughout February and March 2023.
| List by | Sergio Menchero et al. |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
Single Cell Biology 2020
A list of preprints mentioned at the Wellcome Genome Campus Single Cell Biology 2020 meeting.
| List by | Alex Eve |
Antimicrobials: Discovery, clinical use, and development of resistance
Preprints that describe the discovery of new antimicrobials and any improvements made regarding their clinical use. Includes preprints that detail the factors affecting antimicrobial selection and the development of antimicrobial resistance.
| List by | Zhang-He Goh |
Also in the cell biology category:
Developmental regulation: molecular and ecological niches
This conference was held at the Station Biologique de Roscoff (France) and brought together researchers exploring how diverse niche environments shape developmental processes across scales. Spanning topics from ecological and metabolic influences to signalling networks, mechanics and gene regulation, the meeting highlighted the interplay between intrinsic and extrinsic factors in controlling cell fate and tissue organisation. This preList gathers preprints discussed by speakers and poster presenters during the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
November in preprints – DevBio & Stem cell biology
preLighters with expertise across developmental and stem cell biology have nominated a few developmental and stem cell biology (and related) preprints posted in November they’re excited about and explain in a single paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Aline Grata et al. |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
September in preprints – Cell biology edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading list. This month, categories include: (1) Cell organelles and organisation, (2) Cell signalling and mechanosensing, (3) Cell metabolism, (4) Cell cycle and division, (5) Cell migration
| List by | Sristilekha Nath et al. |
July in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell Signalling and Mechanosensing (2) Cell Cycle and Division (3) Cell Migration and Cytoskeleton (4) Cancer Biology (5) Cell Organelles and Organisation
| List by | Girish Kale et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
March in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) cancer biology 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics and genomics 6) other
| List by | Girish Kale et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
February in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry and cell metabolism 2) cell organelles and organisation 3) cell signalling, migration and mechanosensing
| List by | Barbora Knotkova et al. |
Community-driven preList – Immunology
In this community-driven preList, a group of preLighters, with expertise in different areas of immunology have worked together to create this preprint reading list.
| List by | Felipe Del Valle Batalla et al. |
January in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Barbora Knotkova et al. |
December in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) cell cycle and division 2) cell migration and cytoskeleton 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Matthew Davies et al. |
November in preprints – the CellBio edition
This is the first community-driven preList! A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. Categories include: 1) cancer cell biology 2) cell cycle and division 3) cell migration and cytoskeleton 4) cell organelles and organisation 5) cell signalling and mechanosensing 6) genetics/gene expression
| List by | Felipe Del Valle Batalla et al. |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
preLights peer support – preprints of interest
This is a preprint repository to organise the preprints and preLights covered through the 'preLights peer support' initiative.
| List by | preLights peer support |
The Society for Developmental Biology 82nd Annual Meeting
This preList is made up of the preprints discussed during the Society for Developmental Biology 82nd Annual Meeting that took place in Chicago in July 2023.
| List by | Joyce Yu, Katherine Brown |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
Journal of Cell Science meeting ‘Imaging Cell Dynamics’
This preList highlights the preprints discussed at the JCS meeting 'Imaging Cell Dynamics'. The meeting was held from 14 - 17 May 2023 in Lisbon, Portugal and was organised by Erika Holzbaur, Jennifer Lippincott-Schwartz, Rob Parton and Michael Way.
| List by | Helen Zenner |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Alumni picks – preLights 5th Birthday
This preList contains preprints that were picked and highlighted by preLights Alumni - an initiative that was set up to mark preLights 5th birthday. More entries will follow throughout February and March 2023.
| List by | Sergio Menchero et al. |
CellBio 2022 – An ASCB/EMBO Meeting
This preLists features preprints that were discussed and presented during the CellBio 2022 meeting in Washington, DC in December 2022.
| List by | Nadja Hümpfer et al. |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
EMBL Synthetic Morphogenesis: From Gene Circuits to Tissue Architecture (2021)
A list of preprints mentioned at the #EESmorphoG virtual meeting in 2021.
| List by | Alex Eve |
FENS 2020
A collection of preprints presented during the virtual meeting of the Federation of European Neuroscience Societies (FENS) in 2020
| List by | Ana Dorrego-Rivas |
Planar Cell Polarity – PCP
This preList contains preprints about the latest findings on Planar Cell Polarity (PCP) in various model organisms at the molecular, cellular and tissue levels.
| List by | Ana Dorrego-Rivas |
BioMalPar XVI: Biology and Pathology of the Malaria Parasite
[under construction] Preprints presented at the (fully virtual) EMBL BioMalPar XVI, 17-18 May 2020 #emblmalaria
| List by | Dey Lab, Samantha Seah |
1
Cell Polarity
Recent research from the field of cell polarity is summarized in this list of preprints. It comprises of studies focusing on various forms of cell polarity ranging from epithelial polarity, planar cell polarity to front-to-rear polarity.
| List by | Yamini Ravichandran |
TAGC 2020
Preprints recently presented at the virtual Allied Genetics Conference, April 22-26, 2020. #TAGC20
| List by | Maiko Kitaoka et al. |
3D Gastruloids
A curated list of preprints related to Gastruloids (in vitro models of early development obtained by 3D aggregation of embryonic cells). Updated until July 2021.
| List by | Paul Gerald L. Sanchez and Stefano Vianello |
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
EMBL Seeing is Believing – Imaging the Molecular Processes of Life
Preprints discussed at the 2019 edition of Seeing is Believing, at EMBL Heidelberg from the 9th-12th October 2019
| List by | Dey Lab |
Autophagy
Preprints on autophagy and lysosomal degradation and its role in neurodegeneration and disease. Includes molecular mechanisms, upstream signalling and regulation as well as studies on pharmaceutical interventions to upregulate the process.
| List by | Sandra Malmgren Hill |
Lung Disease and Regeneration
This preprint list compiles highlights from the field of lung biology.
| List by | Rob Hynds |
Cellular metabolism
A curated list of preprints related to cellular metabolism at Biorxiv by Pablo Ranea Robles from the Prelights community. Special interest on lipid metabolism, peroxisomes and mitochondria.
| List by | Pablo Ranea Robles |
BSCB/BSDB Annual Meeting 2019
Preprints presented at the BSCB/BSDB Annual Meeting 2019
| List by | Dey Lab |
MitoList
This list of preprints is focused on work expanding our knowledge on mitochondria in any organism, tissue or cell type, from the normal biology to the pathology.
| List by | Sandra Franco Iborra |
Biophysical Society Annual Meeting 2019
Few of the preprints that were discussed in the recent BPS annual meeting at Baltimore, USA
| List by | Joseph Jose Thottacherry |
ASCB/EMBO Annual Meeting 2018
This list relates to preprints that were discussed at the recent ASCB conference.
| List by | Dey Lab, Amanda Haage |
Also in the microbiology category:
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
BioMalPar XVI: Biology and Pathology of the Malaria Parasite
[under construction] Preprints presented at the (fully virtual) EMBL BioMalPar XVI, 17-18 May 2020 #emblmalaria
| List by | Dey Lab, Samantha Seah |
1
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
EMBL Seeing is Believing – Imaging the Molecular Processes of Life
Preprints discussed at the 2019 edition of Seeing is Believing, at EMBL Heidelberg from the 9th-12th October 2019
| List by | Dey Lab |
Antimicrobials: Discovery, clinical use, and development of resistance
Preprints that describe the discovery of new antimicrobials and any improvements made regarding their clinical use. Includes preprints that detail the factors affecting antimicrobial selection and the development of antimicrobial resistance.
| List by | Zhang-He Goh |
Also in the pathology category:
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
COVID-19 / SARS-CoV-2 preprints
List of important preprints dealing with the ongoing coronavirus outbreak. See http://covidpreprints.com for additional resources and timeline, and https://connect.biorxiv.org/relate/content/181 for full list of bioRxiv and medRxiv preprints on this topic
| List by | Dey Lab, Zhang-He Goh |
1
Cellular metabolism
A curated list of preprints related to cellular metabolism at Biorxiv by Pablo Ranea Robles from the Prelights community. Special interest on lipid metabolism, peroxisomes and mitochondria.
| List by | Pablo Ranea Robles |
Also in the physiology category:
Developmental regulation: molecular and ecological niches
This conference was held at the Station Biologique de Roscoff (France) and brought together researchers exploring how diverse niche environments shape developmental processes across scales. Spanning topics from ecological and metabolic influences to signalling networks, mechanics and gene regulation, the meeting highlighted the interplay between intrinsic and extrinsic factors in controlling cell fate and tissue organisation. This preList gathers preprints discussed by speakers and poster presenters during the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
FENS 2020
A collection of preprints presented during the virtual meeting of the Federation of European Neuroscience Societies (FENS) in 2020
| List by | Ana Dorrego-Rivas |
TAGC 2020
Preprints recently presented at the virtual Allied Genetics Conference, April 22-26, 2020. #TAGC20
| List by | Maiko Kitaoka et al. |
Autophagy
Preprints on autophagy and lysosomal degradation and its role in neurodegeneration and disease. Includes molecular mechanisms, upstream signalling and regulation as well as studies on pharmaceutical interventions to upregulate the process.
| List by | Sandra Malmgren Hill |