








Moving beyond P values: Everyday data analysis with estimation plots
Posted on: 1 August 2018 , updated on: 3 August 2018
Preprint posted on 26 July 2018
Article now published in Nature Methods at http://dx.doi.org/10.1038/s41592-019-0470-3
A visual, intuitive and widely accessible tool could finally help us move from asking “does it?” to “how much?”
Selected by Dey LabContext
Statistical analysis in the biological sciences has long been dominated by null-hypothesis significance testing (NHST). Statisticians and quantitatively-minded biologists alike have been crying themselves hoarse about the fallacies and intrinsic limitations associated with this approach for, believe it or not, approximately 75 years1,2. Unfortunately, there has been little consensus on the practical steps needed to achieve significant reform.
The authors illustrate the key limitations of NHST as well as their proposed solution using an experimental setup we are all too familiar with: one containing two groups of data points, representing a control and a test/intervention sample. Such an experiment would be traditionally visualized using bar graphs (Fig 1A), box plots (Fig 1B) or perhaps scatterplots (Fig 1C) and analyzed by a Student’s t-test or related NHST variant.
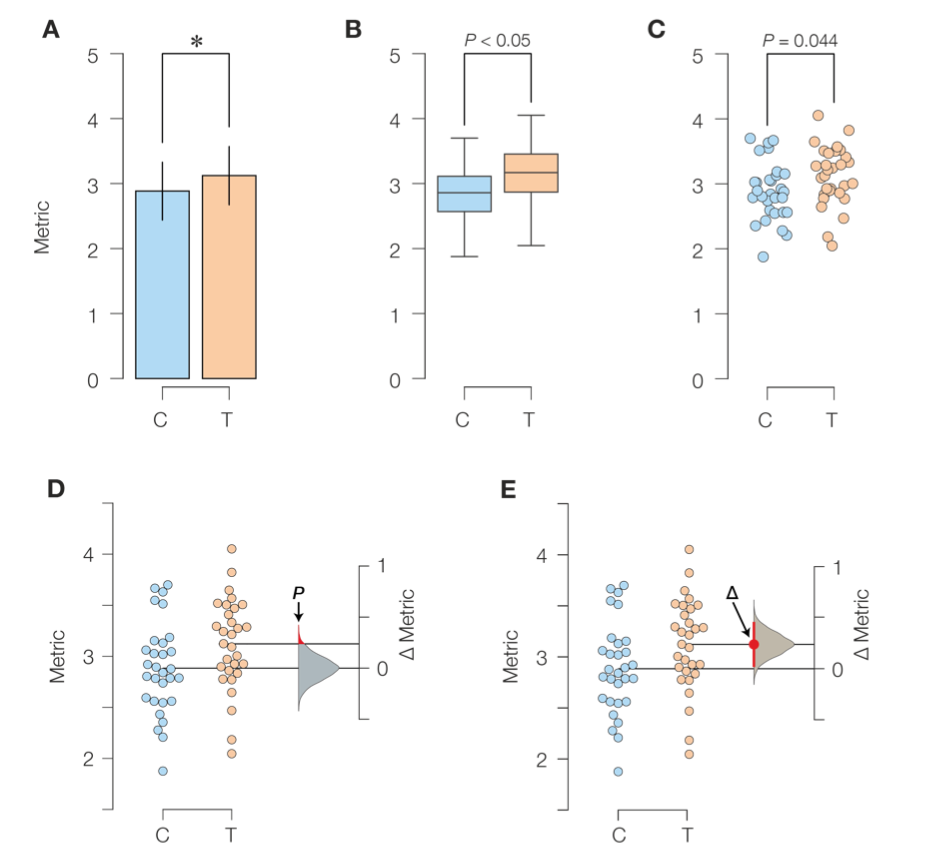
What is wrong with the status quo?
- The NHST focuses purely on a binary decision3 to accept or reject the null hypothesis (that the means of both groups are identical) and diverts attention away from the actual effect size; this is emphasized by bar plots and only moderately mitigated by box and scatter plots.
- Visualizing the null distribution and the p-value threshold (Fig 1D, red tail) helps drive home the issues with NHST. First, even an infinitesimally small intervention to any real system will produce at least some effect, making the zero-effect hypothesis intrinsically flawed4. Second, since the p-value threshold (usually 0.05) actually lies within the tail of the null distribution, we are concluding that control and test samples are different by demonstrating that they are sometimes the same!
How to fix it?
- Estimation plots focus on the difference of means (Fig 1E). The visual representation helps focus attention on the effect size, which is what we (should) actually care about. The 95% confidence interval5 (red bar in Fig 1E), that encompasses the bulk of the ∆ sampling-error distribution (by definition), is more intuitively grasped and much better behaved than the p-value. In this case, we are concluding that control and test samples are different by demonstrating that they are almost always different.
Why I chose this preprint
I loved this preprint! The estimation plot provides a complete yet visually accessible description of the data- and working through the steps in Figure 1 has given me a visual framework to interpret what I thought I understood about hypothesis testing. More importantly, the authors go to great lengths to make estimation plotting broadly accessible- by providing 5 different ways in which to create them, ranging from Python code to a handy web tool that requires no programming experience whatsoever. Go ahead- try it out!
References:
- Berkson, J. Tests of Significance Considered as Evidence. J. Am. Stat. Assoc. 37, 325–335 (1942).
- Halsey, L. G., Curran-Everett, D., Vowler, S. L. & Drummond, G. B. The fickle P value generates irreproducible results. Nat. Methods 12, 179–185 (2015).
- McShane, B. B. & Gal, D. Statistical Significance and the Dichotomization of Evidence. J. Am. Stat. Assoc. 112, 885–895 (2017).
- Cohen, J. The earth is round (p < .05). Am. Psychol. 49, 997–1003 (1994).
- Cumming, G. Understanding The New Statistics. (Routledge, 2011). doi:10.4324/9780203807002
doi: https://doi.org/10.1242/prelights.4025
Read preprint (5 votes)
(5 votes) Sign up to customise the site to your preferences and to receive alerts
Register hereAlso in the cancer biology category:
Nature-Inspired Nanoparticle Adiposomes Enable Targeted Delivery of Hydrophobic Drug for Anti-Cancer Treatment
Elizabeth Pyman
Targeting CXADR-mediated AKT signaling suppresses tumorigenesis and enhances chemotherapy efficacy in Ewing sarcoma
TheLangeLab et al.
Dual inhibition of GTP-bound (ON) and GDP-bound (OFF) KRASG12C suppresses PI3Kα and leads to potent tumor inhibition
Luis Luna Ramírez
Also in the cell biology category:
Combinatorial and Inducible CRISPRa/i Enables Canalized hiPSC Forward Programming and Iterative Refinement via Single-Cell Genomics
Cell-ID
Developmental conversion of the nucleolus into an RNA Polymerase II transcriptional platform in Drosophila spermatocytes
Panagiotis Giannios
Cell position is more important than cell shape or age for the acquisition of cell identity in the brown alga Ectocarpus
Urvashi Goswami
Also in the clinical trials category:
A thirty-year trend of increasing clinical orientation at the National Institutes of Health
AND
Prediction of transformative breakthroughs in biomedical research
Jonathan Townson
Microbial Feast or Famine: dietary carbohydrate composition and gut microbiota metabolic function
Jasmine Talevi
Identifiability-Guided Assessment of Digital Twins in Alzheimer’s Disease Clinical Research and Care
My Nguyen
Also in the developmental biology category:
Disordered protein COSA-2 maintains crossover-specific repair compartments to ensure meiotic crossover maturation
Chee Kiang Ewe
Comprehensive Lineage Tracing Maps the Landscape of Cell Fate Decisions in Mouse Embryogenesis
Béryl Laplace-Builhé, Lucie Hermet
Developmental conversion of the nucleolus into an RNA Polymerase II transcriptional platform in Drosophila spermatocytes
Panagiotis Giannios
Also in the molecular biology category:
Disordered protein COSA-2 maintains crossover-specific repair compartments to ensure meiotic crossover maturation
Chee Kiang Ewe
Combinatorial and Inducible CRISPRa/i Enables Canalized hiPSC Forward Programming and Iterative Refinement via Single-Cell Genomics
Cell-ID
Defective BRCA1-mediated DNA end resection drives tandem duplication formation and FANCM synthetic lethality
Marta San Martin
Also in the neuroscience category:
Behavioral characteristics of an extremely old rhesus macaque in a zoo: Dementia-like symptoms and implications for quality of life of geriatric animals
Stefan Friedrich Wirth
EBV reprograms autoreactive anti-CNS B cells as antigen presenting cells in multiple sclerosis
Léa Bastien et al.
The Endocannabinoid System’s Contribution to Placebo Analgesia
Thomas Nicodemo Arrieta et al.
Also in the scientific communication and education category:
Science should be machine-readable
Theodora Stougiannou
A thirty-year trend of increasing clinical orientation at the National Institutes of Health
AND
Prediction of transformative breakthroughs in biomedical research
Jonathan Townson
DNA Specimen Preservation using DESS and DNA Extraction in Museum Collections: A Case Study Report
Daniel Fernando Reyes Enríquez, Marcus Oliveira
preLists in the cancer biology category:
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
September in preprints – Cell biology edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading list. This month, categories include: (1) Cell organelles and organisation, (2) Cell signalling and mechanosensing, (3) Cell metabolism, (4) Cell cycle and division, (5) Cell migration
| List by | Sristilekha Nath et al. |
July in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell Signalling and Mechanosensing (2) Cell Cycle and Division (3) Cell Migration and Cytoskeleton (4) Cancer Biology (5) Cell Organelles and Organisation
| List by | Girish Kale et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
March in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) cancer biology 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics and genomics 6) other
| List by | Girish Kale et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
February in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry and cell metabolism 2) cell organelles and organisation 3) cell signalling, migration and mechanosensing
| List by | Barbora Knotkova et al. |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
Journal of Cell Science meeting ‘Imaging Cell Dynamics’
This preList highlights the preprints discussed at the JCS meeting 'Imaging Cell Dynamics'. The meeting was held from 14 - 17 May 2023 in Lisbon, Portugal and was organised by Erika Holzbaur, Jennifer Lippincott-Schwartz, Rob Parton and Michael Way.
| List by | Helen Zenner |
CellBio 2022 – An ASCB/EMBO Meeting
This preLists features preprints that were discussed and presented during the CellBio 2022 meeting in Washington, DC in December 2022.
| List by | Nadja Hümpfer et al. |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
Single Cell Biology 2020
A list of preprints mentioned at the Wellcome Genome Campus Single Cell Biology 2020 meeting.
| List by | Alex Eve |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
Lung Disease and Regeneration
This preprint list compiles highlights from the field of lung biology.
| List by | Rob Hynds |
Anticancer agents: Discovery and clinical use
Preprints that describe the discovery of anticancer agents and their clinical use. Includes both small molecules and macromolecules like biologics.
| List by | Zhang-He Goh |
Biophysical Society Annual Meeting 2019
Few of the preprints that were discussed in the recent BPS annual meeting at Baltimore, USA
| List by | Joseph Jose Thottacherry |
Also in the cell biology category:
Developmental regulation: molecular and ecological niches
This conference was held at the Station Biologique de Roscoff (France) and brought together researchers exploring how diverse niche environments shape developmental processes across scales. Spanning topics from ecological and metabolic influences to signalling networks, mechanics and gene regulation, the meeting highlighted the interplay between intrinsic and extrinsic factors in controlling cell fate and tissue organisation. This preList gathers preprints discussed by speakers and poster presenters during the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
November in preprints – DevBio & Stem cell biology
preLighters with expertise across developmental and stem cell biology have nominated a few developmental and stem cell biology (and related) preprints posted in November they’re excited about and explain in a single paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Aline Grata et al. |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
September in preprints – Cell biology edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading list. This month, categories include: (1) Cell organelles and organisation, (2) Cell signalling and mechanosensing, (3) Cell metabolism, (4) Cell cycle and division, (5) Cell migration
| List by | Sristilekha Nath et al. |
July in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell Signalling and Mechanosensing (2) Cell Cycle and Division (3) Cell Migration and Cytoskeleton (4) Cancer Biology (5) Cell Organelles and Organisation
| List by | Girish Kale et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
March in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) cancer biology 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics and genomics 6) other
| List by | Girish Kale et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
February in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry and cell metabolism 2) cell organelles and organisation 3) cell signalling, migration and mechanosensing
| List by | Barbora Knotkova et al. |
Community-driven preList – Immunology
In this community-driven preList, a group of preLighters, with expertise in different areas of immunology have worked together to create this preprint reading list.
| List by | Felipe Del Valle Batalla et al. |
January in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Barbora Knotkova et al. |
December in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) cell cycle and division 2) cell migration and cytoskeleton 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Matthew Davies et al. |
November in preprints – the CellBio edition
This is the first community-driven preList! A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. Categories include: 1) cancer cell biology 2) cell cycle and division 3) cell migration and cytoskeleton 4) cell organelles and organisation 5) cell signalling and mechanosensing 6) genetics/gene expression
| List by | Felipe Del Valle Batalla et al. |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
preLights peer support – preprints of interest
This is a preprint repository to organise the preprints and preLights covered through the 'preLights peer support' initiative.
| List by | preLights peer support |
The Society for Developmental Biology 82nd Annual Meeting
This preList is made up of the preprints discussed during the Society for Developmental Biology 82nd Annual Meeting that took place in Chicago in July 2023.
| List by | Joyce Yu, Katherine Brown |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
Journal of Cell Science meeting ‘Imaging Cell Dynamics’
This preList highlights the preprints discussed at the JCS meeting 'Imaging Cell Dynamics'. The meeting was held from 14 - 17 May 2023 in Lisbon, Portugal and was organised by Erika Holzbaur, Jennifer Lippincott-Schwartz, Rob Parton and Michael Way.
| List by | Helen Zenner |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Alumni picks – preLights 5th Birthday
This preList contains preprints that were picked and highlighted by preLights Alumni - an initiative that was set up to mark preLights 5th birthday. More entries will follow throughout February and March 2023.
| List by | Sergio Menchero et al. |
CellBio 2022 – An ASCB/EMBO Meeting
This preLists features preprints that were discussed and presented during the CellBio 2022 meeting in Washington, DC in December 2022.
| List by | Nadja Hümpfer et al. |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
EMBL Synthetic Morphogenesis: From Gene Circuits to Tissue Architecture (2021)
A list of preprints mentioned at the #EESmorphoG virtual meeting in 2021.
| List by | Alex Eve |
FENS 2020
A collection of preprints presented during the virtual meeting of the Federation of European Neuroscience Societies (FENS) in 2020
| List by | Ana Dorrego-Rivas |
Planar Cell Polarity – PCP
This preList contains preprints about the latest findings on Planar Cell Polarity (PCP) in various model organisms at the molecular, cellular and tissue levels.
| List by | Ana Dorrego-Rivas |
BioMalPar XVI: Biology and Pathology of the Malaria Parasite
[under construction] Preprints presented at the (fully virtual) EMBL BioMalPar XVI, 17-18 May 2020 #emblmalaria
| List by | Dey Lab, Samantha Seah |
1
Cell Polarity
Recent research from the field of cell polarity is summarized in this list of preprints. It comprises of studies focusing on various forms of cell polarity ranging from epithelial polarity, planar cell polarity to front-to-rear polarity.
| List by | Yamini Ravichandran |
TAGC 2020
Preprints recently presented at the virtual Allied Genetics Conference, April 22-26, 2020. #TAGC20
| List by | Maiko Kitaoka et al. |
3D Gastruloids
A curated list of preprints related to Gastruloids (in vitro models of early development obtained by 3D aggregation of embryonic cells). Updated until July 2021.
| List by | Paul Gerald L. Sanchez and Stefano Vianello |
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
EMBL Seeing is Believing – Imaging the Molecular Processes of Life
Preprints discussed at the 2019 edition of Seeing is Believing, at EMBL Heidelberg from the 9th-12th October 2019
| List by | Dey Lab |
Autophagy
Preprints on autophagy and lysosomal degradation and its role in neurodegeneration and disease. Includes molecular mechanisms, upstream signalling and regulation as well as studies on pharmaceutical interventions to upregulate the process.
| List by | Sandra Malmgren Hill |
Lung Disease and Regeneration
This preprint list compiles highlights from the field of lung biology.
| List by | Rob Hynds |
Cellular metabolism
A curated list of preprints related to cellular metabolism at Biorxiv by Pablo Ranea Robles from the Prelights community. Special interest on lipid metabolism, peroxisomes and mitochondria.
| List by | Pablo Ranea Robles |
BSCB/BSDB Annual Meeting 2019
Preprints presented at the BSCB/BSDB Annual Meeting 2019
| List by | Dey Lab |
MitoList
This list of preprints is focused on work expanding our knowledge on mitochondria in any organism, tissue or cell type, from the normal biology to the pathology.
| List by | Sandra Franco Iborra |
ASCB/EMBO Annual Meeting 2018
This list relates to preprints that were discussed at the recent ASCB conference.
| List by | Dey Lab, Amanda Haage |
Also in the clinical trials category:
Autophagy
Preprints on autophagy and lysosomal degradation and its role in neurodegeneration and disease. Includes molecular mechanisms, upstream signalling and regulation as well as studies on pharmaceutical interventions to upregulate the process.
| List by | Sandra Malmgren Hill |
Antimicrobials: Discovery, clinical use, and development of resistance
Preprints that describe the discovery of new antimicrobials and any improvements made regarding their clinical use. Includes preprints that detail the factors affecting antimicrobial selection and the development of antimicrobial resistance.
| List by | Zhang-He Goh |
Also in the developmental biology category:
Developmental regulation: molecular and ecological niches
This conference was held at the Station Biologique de Roscoff (France) and brought together researchers exploring how diverse niche environments shape developmental processes across scales. Spanning topics from ecological and metabolic influences to signalling networks, mechanics and gene regulation, the meeting highlighted the interplay between intrinsic and extrinsic factors in controlling cell fate and tissue organisation. This preList gathers preprints discussed by speakers and poster presenters during the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
November in preprints – DevBio & Stem cell biology
preLighters with expertise across developmental and stem cell biology have nominated a few developmental and stem cell biology (and related) preprints posted in November they’re excited about and explain in a single paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Aline Grata et al. |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
BSDB/GenSoc Spring Meeting 2024
A list of preprints highlighted at the British Society for Developmental Biology and Genetics Society joint Spring meeting 2024 at Warwick, UK.
| List by | Joyce Yu, Katherine Brown |
GfE/ DSDB meeting 2024
This preList highlights the preprints discussed at the 2024 joint German and Dutch developmental biology societies meeting that took place in March 2024 in Osnabrück, Germany.
| List by | Joyce Yu |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
preLights peer support – preprints of interest
This is a preprint repository to organise the preprints and preLights covered through the 'preLights peer support' initiative.
| List by | preLights peer support |
The Society for Developmental Biology 82nd Annual Meeting
This preList is made up of the preprints discussed during the Society for Developmental Biology 82nd Annual Meeting that took place in Chicago in July 2023.
| List by | Joyce Yu, Katherine Brown |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
Journal of Cell Science meeting ‘Imaging Cell Dynamics’
This preList highlights the preprints discussed at the JCS meeting 'Imaging Cell Dynamics'. The meeting was held from 14 - 17 May 2023 in Lisbon, Portugal and was organised by Erika Holzbaur, Jennifer Lippincott-Schwartz, Rob Parton and Michael Way.
| List by | Helen Zenner |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Alumni picks – preLights 5th Birthday
This preList contains preprints that were picked and highlighted by preLights Alumni - an initiative that was set up to mark preLights 5th birthday. More entries will follow throughout February and March 2023.
| List by | Sergio Menchero et al. |
CellBio 2022 – An ASCB/EMBO Meeting
This preLists features preprints that were discussed and presented during the CellBio 2022 meeting in Washington, DC in December 2022.
| List by | Nadja Hümpfer et al. |
2nd Conference of the Visegrád Group Society for Developmental Biology
Preprints from the 2nd Conference of the Visegrád Group Society for Developmental Biology (2-5 September, 2021, Szeged, Hungary)
| List by | Nándor Lipták |
Fibroblasts
The advances in fibroblast biology preList explores the recent discoveries and preprints of the fibroblast world. Get ready to immerse yourself with this list created for fibroblasts aficionados and lovers, and beyond. Here, my goal is to include preprints of fibroblast biology, heterogeneity, fate, extracellular matrix, behavior, topography, single-cell atlases, spatial transcriptomics, and their matrix!
| List by | Osvaldo Contreras |
EMBL Synthetic Morphogenesis: From Gene Circuits to Tissue Architecture (2021)
A list of preprints mentioned at the #EESmorphoG virtual meeting in 2021.
| List by | Alex Eve |
EMBL Conference: From functional genomics to systems biology
Preprints presented at the virtual EMBL conference "from functional genomics and systems biology", 16-19 November 2020
| List by | Jesus Victorino |
Single Cell Biology 2020
A list of preprints mentioned at the Wellcome Genome Campus Single Cell Biology 2020 meeting.
| List by | Alex Eve |
Society for Developmental Biology 79th Annual Meeting
Preprints at SDB 2020
| List by | Irepan Salvador-Martinez, Martin Estermann |
FENS 2020
A collection of preprints presented during the virtual meeting of the Federation of European Neuroscience Societies (FENS) in 2020
| List by | Ana Dorrego-Rivas |
Planar Cell Polarity – PCP
This preList contains preprints about the latest findings on Planar Cell Polarity (PCP) in various model organisms at the molecular, cellular and tissue levels.
| List by | Ana Dorrego-Rivas |
Cell Polarity
Recent research from the field of cell polarity is summarized in this list of preprints. It comprises of studies focusing on various forms of cell polarity ranging from epithelial polarity, planar cell polarity to front-to-rear polarity.
| List by | Yamini Ravichandran |
TAGC 2020
Preprints recently presented at the virtual Allied Genetics Conference, April 22-26, 2020. #TAGC20
| List by | Maiko Kitaoka et al. |
3D Gastruloids
A curated list of preprints related to Gastruloids (in vitro models of early development obtained by 3D aggregation of embryonic cells). Updated until July 2021.
| List by | Paul Gerald L. Sanchez and Stefano Vianello |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
EDBC Alicante 2019
Preprints presented at the European Developmental Biology Congress (EDBC) in Alicante, October 23-26 2019.
| List by | Sergio Menchero et al. |
EMBL Seeing is Believing – Imaging the Molecular Processes of Life
Preprints discussed at the 2019 edition of Seeing is Believing, at EMBL Heidelberg from the 9th-12th October 2019
| List by | Dey Lab |
SDB 78th Annual Meeting 2019
A curation of the preprints presented at the SDB meeting in Boston, July 26-30 2019. The preList will be updated throughout the duration of the meeting.
| List by | Alex Eve |
Lung Disease and Regeneration
This preprint list compiles highlights from the field of lung biology.
| List by | Rob Hynds |
Young Embryologist Network Conference 2019
Preprints presented at the Young Embryologist Network 2019 conference, 13 May, The Francis Crick Institute, London
| List by | Alex Eve |
Pattern formation during development
The aim of this preList is to integrate results about the mechanisms that govern patterning during development, from genes implicated in the processes to theoritical models of pattern formation in nature.
| List by | Alexa Sadier |
BSCB/BSDB Annual Meeting 2019
Preprints presented at the BSCB/BSDB Annual Meeting 2019
| List by | Dey Lab |
Zebrafish immunology
A compilation of cutting-edge research that uses the zebrafish as a model system to elucidate novel immunological mechanisms in health and disease.
| List by | Shikha Nayar |
Also in the molecular biology category:
Developmental regulation: molecular and ecological niches
This conference was held at the Station Biologique de Roscoff (France) and brought together researchers exploring how diverse niche environments shape developmental processes across scales. Spanning topics from ecological and metabolic influences to signalling networks, mechanics and gene regulation, the meeting highlighted the interplay between intrinsic and extrinsic factors in controlling cell fate and tissue organisation. This preList gathers preprints discussed by speakers and poster presenters during the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
SciELO preprints – From 2025 onwards
SciELO has become a cornerstone of open, multilingual scholarly communication across Latin America. Its preprint server, SciELO preprints, is expanding the global reach of preprinted research from the region (for more information, see our interview with Carolina Tanigushi). This preList brings together biological, English language SciELO preprints to help readers discover emerging work from the Global South. By highlighting these preprints in one place, we aim to support visibility, encourage early feedback, and showcase the vibrant research communities contributing to SciELO’s open science ecosystem.
| List by | Carolina Tanigushi |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
September in preprints – Cell biology edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading list. This month, categories include: (1) Cell organelles and organisation, (2) Cell signalling and mechanosensing, (3) Cell metabolism, (4) Cell cycle and division, (5) Cell migration
| List by | Sristilekha Nath et al. |
June in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell organelles and organisation (2) Cell signaling and mechanosensation (3) Genetics/gene expression (4) Biochemistry (5) Cytoskeleton
| List by | Barbora Knotkova et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
Keystone Symposium – Metabolic and Nutritional Control of Development and Cell Fate
This preList contains preprints discussed during the Metabolic and Nutritional Control of Development and Cell Fate Keystone Symposia. This conference was organized by Lydia Finley and Ralph J. DeBerardinis and held in the Wylie Center and Tupper Manor at Endicott College, Beverly, MA, United States from May 7th to 9th 2025. This meeting marked the first in-person gathering of leading researchers exploring how metabolism influences development, including processes like cell fate, tissue patterning, and organ function, through nutrient availability and metabolic regulation. By integrating modern metabolic tools with genetic and epidemiological insights across model organisms, this event highlighted key mechanisms and identified open questions to advance the emerging field of developmental metabolism.
| List by | Virginia Savy, Martin Estermann |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
February in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry and cell metabolism 2) cell organelles and organisation 3) cell signalling, migration and mechanosensing
| List by | Barbora Knotkova et al. |
Community-driven preList – Immunology
In this community-driven preList, a group of preLighters, with expertise in different areas of immunology have worked together to create this preprint reading list.
| List by | Felipe Del Valle Batalla et al. |
January in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell migration 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) genetics/gene expression
| List by | Barbora Knotkova et al. |
2024 Hypothalamus GRC
This 2024 Hypothalamus GRC (Gordon Research Conference) preList offers an overview of cutting-edge research focused on the hypothalamus, a critical brain region involved in regulating homeostasis, behavior, and neuroendocrine functions. The studies included cover a range of topics, including neural circuits, molecular mechanisms, and the role of the hypothalamus in health and disease. This collection highlights some of the latest advances in understanding hypothalamic function, with potential implications for treating disorders such as obesity, stress, and metabolic diseases.
| List by | Nathalie Krauth |
BSCB-Biochemical Society 2024 Cell Migration meeting
This preList features preprints that were discussed and presented during the BSCB-Biochemical Society 2024 Cell Migration meeting in Birmingham, UK in April 2024. Kindly put together by Sara Morais da Silva, Reviews Editor at Journal of Cell Science.
| List by | Reinier Prosee |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
9th International Symposium on the Biology of Vertebrate Sex Determination
This preList contains preprints discussed during the 9th International Symposium on the Biology of Vertebrate Sex Determination. This conference was held in Kona, Hawaii from April 17th to 21st 2023.
| List by | Martin Estermann |
Alumni picks – preLights 5th Birthday
This preList contains preprints that were picked and highlighted by preLights Alumni - an initiative that was set up to mark preLights 5th birthday. More entries will follow throughout February and March 2023.
| List by | Sergio Menchero et al. |
CellBio 2022 – An ASCB/EMBO Meeting
This preLists features preprints that were discussed and presented during the CellBio 2022 meeting in Washington, DC in December 2022.
| List by | Nadja Hümpfer et al. |
EMBL Synthetic Morphogenesis: From Gene Circuits to Tissue Architecture (2021)
A list of preprints mentioned at the #EESmorphoG virtual meeting in 2021.
| List by | Alex Eve |
FENS 2020
A collection of preprints presented during the virtual meeting of the Federation of European Neuroscience Societies (FENS) in 2020
| List by | Ana Dorrego-Rivas |
ECFG15 – Fungal biology
Preprints presented at 15th European Conference on Fungal Genetics 17-20 February 2020 Rome
| List by | Hiral Shah |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
Lung Disease and Regeneration
This preprint list compiles highlights from the field of lung biology.
| List by | Rob Hynds |
MitoList
This list of preprints is focused on work expanding our knowledge on mitochondria in any organism, tissue or cell type, from the normal biology to the pathology.
| List by | Sandra Franco Iborra |
Also in the neuroscience category:
preLighters’ choice – Handpicked DevBio preprints
preLighters with expertise across developmental and stem cell biology have nominated a few developmental biology (and related) preprints they’re excited about and explain in a few paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Theodora Stougiannou et al. |
BSDB Spring Meeting: Molecules to Morphogenesis
The British Society for Developmental Biology (BSDB) Spring Meeting Molecules to Morphogenesis was held from 23–26 March 2026 at the University of Warwick (UK). This meeting brought together a vibrant community of researchers to discuss how molecular mechanisms are integrated across scales to drive morphogenesis, spanning diverse model systems and approaches. This preList contains preprints by presenters from the talk and poster sessions at the meeting. Please do get in touch at preLights@biologists.com if you notice any relevant preprints that we may have missed.
| List by | Ingrid Tsang |
Keystone Symposium on Stem Cell Models in Embryology 2026
The Keystone Symposium on Stem Cell Models in Embryology, 2026, was organised by Jun Wu (UT Southwestern), Jianping Fu (University of Michigan) and Miki Ebisuya (TU Dresden) and held at Asilomar Conference Grounds in California (US). The meeting discussed recent advances made in establishing stem-cell-based embryo models, what fundamental insights into developmental processes have been gleaned from them, as well as how they are beginning to be applied more widely. This prelist contains preprints by presenters at the talk and poster sessions at the conference, which our Reviews Editor in attendance spotted. Please do reach out to preLights@biologists.com if you notice any that we’ve missed.
| List by | Ingrid Tsang |
November in preprints – DevBio & Stem cell biology
preLighters with expertise across developmental and stem cell biology have nominated a few developmental and stem cell biology (and related) preprints posted in November they’re excited about and explain in a single paragraph why. Concise preprint highlights, prepared by the preLighter community – a quick way to spot upcoming trends, new methods and fresh ideas.
| List by | Aline Grata et al. |
October in preprints – DevBio & Stem cell biology
Each month, preLighters with expertise across developmental and stem cell biology nominate a few recent developmental and stem cell biology (and related) preprints they’re excited about and explain in a single paragraph why. Short, snappy picks from working scientists — a quick way to spot fresh ideas, bold methods and papers worth reading in full. These preprints can all be found in the October preprint list published on the Node.
| List by | Deevitha Balasubramanian et al. |
October in preprints – Cell biology edition
Different preLighters, with expertise across cell biology, have worked together to create this preprint reading list for researchers with an interest in cell biology. This month, most picks fall under (1) Cell organelles and organisation, followed by (2) Mechanosignaling and mechanotransduction, (3) Cell cycle and division and (4) Cell migration
| List by | Matthew Davies et al. |
July in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: (1) Cell Signalling and Mechanosensing (2) Cell Cycle and Division (3) Cell Migration and Cytoskeleton (4) Cancer Biology (5) Cell Organelles and Organisation
| List by | Girish Kale et al. |
May in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) Biochemistry/metabolism 2) Cancer cell Biology 3) Cell adhesion, migration and cytoskeleton 4) Cell organelles and organisation 5) Cell signalling and 6) Genetics
| List by | Barbora Knotkova et al. |
April in preprints – the CellBio edition
A group of preLighters, with expertise in different areas of cell biology, have worked together to create this preprint reading lists for researchers with an interest in cell biology. This month, categories include: 1) biochemistry/metabolism 2) cell cycle and division 3) cell organelles and organisation 4) cell signalling and mechanosensing 5) (epi)genetics
| List by | Vibha SINGH et al. |
Biologists @ 100 conference preList
This preList aims to capture all preprints being discussed at the Biologists @100 conference in Liverpool, UK, either as part of the poster sessions or the (flash/short/full-length) talks.
| List by | Reinier Prosee, Jonathan Townson |
2024 Hypothalamus GRC
This 2024 Hypothalamus GRC (Gordon Research Conference) preList offers an overview of cutting-edge research focused on the hypothalamus, a critical brain region involved in regulating homeostasis, behavior, and neuroendocrine functions. The studies included cover a range of topics, including neural circuits, molecular mechanisms, and the role of the hypothalamus in health and disease. This collection highlights some of the latest advances in understanding hypothalamic function, with potential implications for treating disorders such as obesity, stress, and metabolic diseases.
| List by | Nathalie Krauth |
‘In preprints’ from Development 2022-2023
A list of the preprints featured in Development's 'In preprints' articles between 2022-2023
| List by | Alex Eve, Katherine Brown |
CSHL 87th Symposium: Stem Cells
Preprints mentioned by speakers at the #CSHLsymp23
| List by | Alex Eve |
Journal of Cell Science meeting ‘Imaging Cell Dynamics’
This preList highlights the preprints discussed at the JCS meeting 'Imaging Cell Dynamics'. The meeting was held from 14 - 17 May 2023 in Lisbon, Portugal and was organised by Erika Holzbaur, Jennifer Lippincott-Schwartz, Rob Parton and Michael Way.
| List by | Helen Zenner |
FENS 2020
A collection of preprints presented during the virtual meeting of the Federation of European Neuroscience Societies (FENS) in 2020
| List by | Ana Dorrego-Rivas |
ASCB EMBO Annual Meeting 2019
A collection of preprints presented at the 2019 ASCB EMBO Meeting in Washington, DC (December 7-11)
| List by | Madhuja Samaddar et al. |
SDB 78th Annual Meeting 2019
A curation of the preprints presented at the SDB meeting in Boston, July 26-30 2019. The preList will be updated throughout the duration of the meeting.
| List by | Alex Eve |
Autophagy
Preprints on autophagy and lysosomal degradation and its role in neurodegeneration and disease. Includes molecular mechanisms, upstream signalling and regulation as well as studies on pharmaceutical interventions to upregulate the process.
| List by | Sandra Malmgren Hill |
Young Embryologist Network Conference 2019
Preprints presented at the Young Embryologist Network 2019 conference, 13 May, The Francis Crick Institute, London
| List by | Alex Eve |